- Published on
From Serverless to Web3
- Authors
- Name
- Chance Jiang
- @chancejiang

In this essay, we're going to look at similarities in engineering between blockchain app and serverless app development. So that teams who's been working with serverless stacks can map out an engineering, product or resource governance road-maps towards any web3 products.
This essay was first published as 《从无服务器到 Web3》 in Chinese at ifanr.com.
Serverless app developers, such as those working on ifanr Cloud, a serverless backend for mobile app and MiniApp, has been enjoying the hassle-free benefits of running their mobile apps without caring about the lower primitives such as server node, memory, and bandwidth allocation, as typically offered by cloud providers.
Now that dApps and blockchains are taking off. dApp developers are working against sets of APIs offered by the blockchain they chose to integrate with, also without worrying about the underlying compute resources or primitives.
The difference and similarities
On the surface, blockchain and serverless computing resources' organizations and service models seem to have few similarities. Serverless is stateless, blockchain is stateful; serverless is ephemeral, blockchain is persistent; serverless processing relies on trust between app developers and the serverless provider; blockchain is designed to be trusted via a trustless model; serverless has lower cost to scale, while blockchain costs higher to scale because of the trade-off among decentralization, security and performance.
Looking closer, serverless and blockchain share a fair amount of similarities. For example, both are designed for event-driven and highly distributed apps. They both process client code as functions--running on a layer above the server level. They complement each other in terms of app state persistence. Serverless typically doesn't persist app state or relying on separate database serverless for this purpose. Blockchain can be used as a state machine for validating transactions.
dApps depend on both on-chain and off-chain processing
The blockchain processing model differs significantly from serverless processing. Not only do most serverless platforms support multiple language, but the goal for serverless processing is one-time processing.
Processing the same transaction on a concurrent basis is antithetical to the serverless processing philosophy. Within blockchain platforms, however, this concurrent identical processing model is a key feature--ensuring and maintaining the blockchain as a validated and trusted source of transaction history and current state.
Given the closed nature of blockchain processing, there is no need--nor any entry way--for serverless processing of on-chain transactions for execution of smart contracts. However, there is a tremendous amount of need for processing off-chain transactions--especially in terms of setting up transactions, helping to perfect transactions, and addressing post-transaction workflows.
Why is there such a need for off-chain transactions? The reason are because,
On-chain processing capabilities are severely limited and
on-chain data storage is severely limited.
As a result, off-chain data processing will need to take place for transactions that are complex and/or data-heavy.
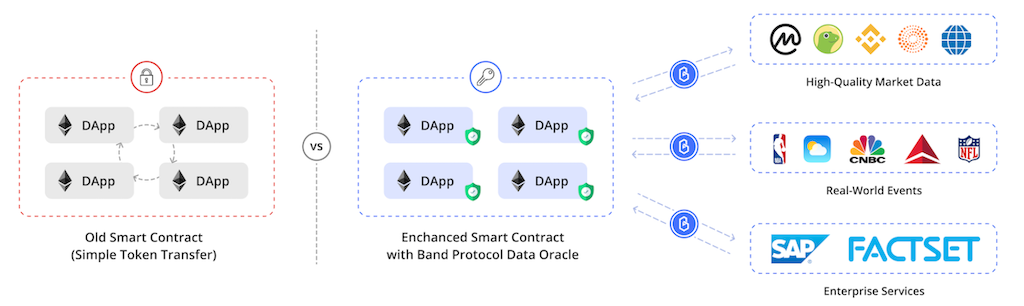
To make effective dApps that relies on blockchain to work on its limited capabilities, on-chain transaction logic needs to be kept to a minimum in order to achieve effective transaction through-puts. Cost mechanisms for using a blockchain, ones that provides reward to blockchain for processing transactions and operating the networks--also impose costs for dApp's transaction cost on blockchain.
Without the "gas" charged for transaction processing, transacting parties would get free rides on the network. In addition, they could overwhelm the blockchain network's capacity--very much like a DDoS attack on a traditional website.
To arrive at the optimal performance, cost, and consistency for each transaction, blockchain app needs to meet computing requirements of both on-chain and off-chain business logic. This also applies to processing on-chain and off-chain data. As a result, effective blockchain design means using the blockchain network for only the most minimal amount of data processing and data storage necessary to perfect and preserve the transaction.
Blockchain and serverless compliments each other in data-processing. Since a dApp depends on both on-chain and off-chain processing, the split between them means that off-chain parts of the app must be able to set up transactions and manage any post-processing needs. Keep in mind that blockchain provides a trusted logs of transactions--but parties using that transaction do need to do so on-chain.
The limitations for storing data on-chain also has implications for serverless processing. Any data that is supporting a transaction will need to be digitally preserved and linked as part of the transaction--like the actual contract that is recorded in the blockchain as being signed. Services are being developed to perform this capability on some public blockchains, and it's now officially called Data Oracle. BandChain, for example, is a high-performance public blockchain that allows anyone to make a request for APIs and services available on the traditional web. It is built on top of the Cosmos SDK, and utilizes Tendermint's Byzantine Fault Tolerance consensus algorithm to reach immediate finality. This finality is specifically reached upon getting confirmations from a sufficient number of block validators. For private blockchain (or permissioned blockchain) networks, potential candidates for serverless processing include preparing the data, validating it, and accessing it post-processing.
The difference between what is processed on-chain vs. off-chain largely comes down to the trust levels among the different parties using the same app. On-chain processing is designed to be trustless--meaning the parties do not have to trust each other in order to perform a transaction. Off-china processing performed by one party in a serverless environment is situated for cases where 1) there is no transaction effected, 2)two or more parties trust each other to forego any sort of consensus algorithm, or 3) there is a consensus algorithm in place to verify the result of the off-chain processing. This is where Data Oracle comes in lately as a new feature for public (permissionedless) blockchain.
The catalyst of event-driven architectures
Blockchain and serverless processing are two independent technical innovations which are markedly different, but they share a number of things in common. While serverless is intended to be stateless, blockchain provides a publicly and independently verifiable way to maintain transactional states.
As app patterns quickly evolve to event-driven architectures, the need for independently verifiable transactional states will increase--and the more likely the serverless and blockchain will be used together. the use case for this combination is especially true in private and/or permissionedless blockchains where the trust level is higher, and the usee of external components and services more tolerable.
Take BandChain as example, it acts as a middle layer operating between the smart contracts platforms, dApps, and the various data providers. As shown in diagram below, only an event-driven architecture can glue together apps built on both blockchain and serverless. In this case, the data oracle's job is to 1) handle data requests coming from the dApps, 2) query the data from the corresponding providers, and 3) report the results back to the application.
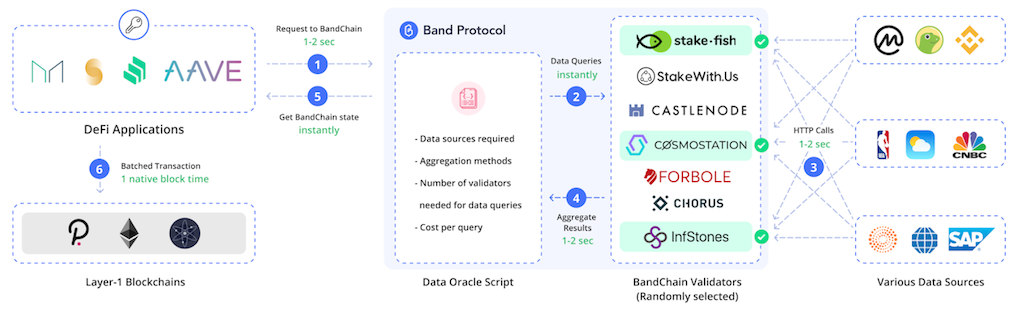
Looking ahead, the differences and similarities between serverless and blockchain show how the two complement each other when apps or dApps are built on both in order to get the best of both worlds. dApps, in particular, benefits from both the event-driven and data oracle design space, and this is where the web2 and the web3 worlds converge and integrate. dApp built this way definitely is best engineered by developers who's been used to building apps on serverless platforms, such as ifanr Cloud. This is because serverless app builders are naturally more focused on business. They are going to have easier time constructing performant dApps leveraging both on-chain and off-chain data.
If you're scratching your head while reading this piece, you are not alone. Me too. As I'm writing down all the concepts I've just acquired in order to explore, at least in theory, what the future of (mobile) apps backend service shall look like.